
A SPELLING CORRECTION MODEL FOR END-TO-END SPEECH RECOGNITION
Jinxi Guo1∗ , Tara N. Sainath2 , Ron J. Weiss2 1University of California, Los Angeles, USA 2Google Inc., USA lennyguo@g.ucla.edu, {tsainath, ronw}@google.com
ABSTRACT
음성 인식을 위한 attention 기반 sequence to sequence 모델은 단일 신경망을 사용하여 음향 모델, 언어 모델 (LM) 및 정렬 메커니즘을 공동 훈련하며 오디오-텍스트 쌍만 필요하다. 따라서 end-to-end 모델에서 언어 모델은 오디오-텍스트 쌍에서만 훈련되므로 희귀 단어에서 특히 성능 저하가 발생한다. 텍스트 전용(text-only) 데이터로 훈련된 외부 LM을 end-to-end 프레임 워크에 통합하는 다양한 시도가 있었지만 모델의 특징적인 오류 분포를 고려한 것은 없었다. 이 논문에서는 이러한 오류를 수정하기 위해 맞춤법 수정 (SC) 모델을 훈련하여 텍스트 전용 데이터를 활용하는 새로운 접근 방식을 제안한다. LibriSpeech 데이터 셋에서, 제안된 모델은 최상위 ASR 가설을 직접 수정하기 때문에 WER이 baseline 모델에 비해 18.6 % 상대적으로 개선되고, 외부 LM을 사용하여 확장된 n-best 목록을 추가로 재 채점할 때 29.0 % 상대적인 개선을 보여준다.
1. INTRODUCTION
ASR (자동 음성 인식)을 위한 end-to-end 모델은 기존 ASR 시스템에서 개별 구성 요소 (즉, 음향, 발음 및 언어 모델)를 단일 신경망으로 합한 방법으로 최근 인기를 얻었다[1, 2, 3, 4]. Listen, Attend and Spell (LAS) 모델 [1]은 강력한 기존의 모델 [5]과 비교하여 음성 인식에서 경쟁력 있는 성능을 보여준 모델 중 하나이다.
End-to-end 모델 훈련에는 오디오-텍스트 쌍이 필요한데, 많은 텍스트 데이터로 훈련되는 기존의 언어 모델 (LM)에 비해 훨씬 적은 데이터로 훈련된다. 그로 인해 end-to-end 모델은 오디오-텍스트 훈련 세트의 발화에 희귀 단어가 포함되면 잘 동작하지 않는다. 이 문제를 해결하기 위해 텍스트 데이터로만 훈련된 RNN-LM을 end-to-end 프레임 워크에 통합하는 다양한 연구가 있었다. 이러한 접근 방식에는 end-to-end 모델 [1]에서 n-best 디코딩 결과 재 채점 혹은 RNN-LM과 1차 통과 빔 검색 융합이 있다. 2, 6, 7, 8
RNN-LM 융합 기술은 일부 꼬리 단어를 수정하기는 하지만 수많은 희귀 단어와 고유 명사 오류가 여전히 존재한다. 한 가지 가설은 LM이 end-to-end 모델이 만드는 오류를 수정하기 위한 목적으로 end-to-end 모델에 통합되지 않는다는 것이다. 특히, LM은 (a) 훈련 데이터의 일부 손실 (deep, cold fusion)을 최소화하기 위해 융합되거나 (b) 훈련 목표없이 디코딩하는 동안 외부적으로 통합된다. (rescoring, shallow fusion).
이 논문의 목표는 시스템에서 발생하는 오류를 수정하기 위해 텍스트 전용 데이터로 훈련된 모듈을 end-to-end 프레임 워크에 통합하는 것이다. 특히, 역 번역과 유사하게 TTS (text-to-speech) 시스템을 사용하여 해당 오디오 신호를 합성하기 위해 텍스트만 있는 데이터를 사용한다[9]. 그 다음 TTS 출력에서 baseline LAS 음성 인식기를 실행해 오류 가설과 그에 상응하는 ground-truth를 나타내는 텍스트-텍스트 쌍을 생성한다. 이러한 텍스트-텍스트 쌍에 맞춤법 교정(SC) 모델을 훈련시켜 첫 번째 통과에서 발생할 수 있는 오류를 수정한다. 논문에서는 LAS 모델의 오류 분포를 포함하지 않는 텍스트 데이터를 통합하는 두 가지 다른 접근 방식을 비교한다.
관련 연구의 경우 [10]은 ASR의 오류 수정에 대한 이전 작업의 전반적인 내용이다. 그들 중 소수만 오류를 자동으로 감지하고 수정할 수 있다. [11]은 동시 발생 분석으로 ASR 오류 감지 및 교정기를 구축했다. [12]은 외부 N-gram 데이터 셋를 기반 ASR 오류 후 처리. 최근에 [13]은 언어 교정 작업을 위해 이 논문과 유사한 attention 기반 네트워크 아키텍처를 제안했다.
이 논문에서는 960 시간 LibriSpeech에 대한 접근 방식을 평가한다. 제안된 철자 교정(SC) 모델이 LAS에서 나온 최상위 가설을 직접 수정할 때 WER이 18.6 % 상대적으로 개선되고, 외부 LM을 사용하여 모델에 의해 생성된 확장 된 n-best 목록을 추가로 재 채점할 때 29.0 %의 상대적 개선이 이루어졌다.
2. BASELINE RECOGNITION MODEL
| 이 논문의 실험에 사용된 baseline 모델은 LAS에서 영향을 받은 인코더-디코더 아키텍처로 [14]의 논무에 기반을 두고 있다. 인코더는 mel spectrogram feature x를 입력으로 받고, higher order feature h-enc에 매핑하는 합성곱 LSTM 계층 스택으로 구성된다. 인코더 출력은 attention 메커니즘으로 전달되어 입력 오디오 시퀀스를 텍스트로 나타내는 출력 시퀀스와 정렬하여 다음 출력 기호 yi를 예측하는 데 사용할 인코더 프레임을 결정한다. attention의 출력은 디코더에 전달되는 컨텍스트 벡터 ci다. 마지막으로 디코더는 attention 컨텍스트 ci와 이전 예측 yi-1의 임베딩을 가져와 로짓 h-dec을 생성한다. 이 로짓은 소프트 맥스로 전달되어 출력 토큰에 대한 확률 분포 P(yi | h-dec)를 계산한다. 디코더는 언어 모델과 유사하다고 할 수 있다. 모델은 훈련 데이터에서 교차 엔트로피 손실을 최소화하도록 훈련되었다. 디코더는 일련의 단어 단위(word piece unit) yi를 출력한다. [5, 15, 16]. |
3. UTILIZING TEXT-ONLY DATA
3.1. External LM
텍스트 데이터를 통합하는 일반적인 접근 방식은 텍스트 데이터 [1, 2, 6, 7, 8]에서 RNN-LM을 훈련시킨 다음 제안된 다양한 메커니즘을 통해 빔 검색 디코딩 중에 LM을 통합하는 것이다.
예를 들어, [1]은 단순히 LM을 사용하여 LAS가 생성 한 n-best 가설을 다시 채점함으로써 상당한 개선을 보여주었다. [2]는 빔 탐색의 각 단계에서 LAS와 LM 간의 로그 선형 interpolation을 수행하여 이 아이디어를 확장했다. 이 방법을 shallow fusion(얕은 융합)이라고 한다. 얕은 융합은 [6, 7]에서 더 연구되었다. Gulcehre 등 [17]은 은닉 상태를 융합하여 외부 LM을 인코더-디코더에 통합하는 deep fusion 방법을 제안했다. [18]에서는 조기 훈련 통합을 수행하여 deep fusion을 수정 한 cold fusion이 제안되었다. 이 논문에서는 [1]과 유사한 n-best rescoring에 중점을 둔다.
| LM rescoring은 3.3.3 절에서 소개할 맞춤법 교정기를 평가하는 것을 더 쉽게 하므로 공정한 비교를 위해 기준 LAS 모델에 대해서도 동일하게 수행했다. 특히 추론하는 동안 우리의 목표는 LAS 모델에서 P (y | x) 및 LM에서 PLM (y)의 점수가 주어지면 가장 가능성이 높은 하위 단어 단위 시퀀스를 찾는 것이다. |

여기서 λ(람다)는 held-out 세트에서 결정된 interpolation(보간) 가중치이다.
3.2. Training on synthesized speech
또 다른 접근 방식은 텍스트 전용 데이터를 사용해 TTS (텍스트 음성 변환) 시스템으로 오디오 텍스트 훈련 데이터를 합성하는 것이다. 유사한 접근 방식이 기계 번역에서 연구되었다. 여기서 Sennrich [9]는 원본 언어로 해당 텍스트를 생성하기 위해 대상 언어의 비교되지 않은 텍스트를 사전 훈련된 “역 번역”모델에 전달했다. 그런 다음이 합성 데이터를 사용하여 번역 모델을 교육하기 위해 기존 병렬 교육 데이터를 보강했다. 이 작업에서 우리는 병렬 WaveNet [19]에 기반한 고품질 TTS 시스템을 사용하여 텍스트 전용 데이터를 합성하고 LAS 모델을 훈련할 때 결과 합성 오디오를 사용한다. 유사한 접근 방식이 최근에 음성 인식에 적용되었다.[20]
3.3. Spelling correction model (SC Model)
텍스트 훈련 데이터를 통합하기 위한 위의 접근 방식의 단점은 음성 인식기에 의해 생성된 특성 오류 분포를 고려하지 않는다는 것이다. 이 섹션에서는 LAS 인식기에서 생성 된 오류를 명시적으로 수정하기 위해 supervised “맞춤법 수정”모델을 훈련하여 텍스트 전용 데이터를 활용하는 새로운 접근 방식을 제안한다. 직관적으로 이 작업은 LAS 모델의 기존 언어 모델링 기능을 활용할 수 있기 때문에 비지도 언어 모델링보다 간단하다. RNN-LM에서와 같이 주변 컨텍스트를 기반으로 단어를 방출할 가능성을 예측하는 대신 SC 모델은 LAS 출력에서 가능한 오류를 식별하고 대안을 제안하기만 하면 된다. baseline LAS 모델은 이미 상대적으로 낮은 단어 오류율을 가지고 있기 때문에 대부분의 경우 이 작업은 단순히 입력 내용을 출력에 직접 복사하는 것으로 줄어든다.
3.3.1. Training data
SC 모델을 훈련하려면 수정할 LAS 가설과 ground truth 텍스트 시퀀스로 구성된 병렬 텍스트 훈련 세트가 필요하다. Baseline LAS 모델의 오류 분포를 나타내는 텍스트 전용 데이터에서 훈련 코퍼스를 생성하기 위해 텍스트 코퍼스에서 텍스트 시퀀스 {y1, y2, …}를 사용하여 TTS 발화 {u1, u2, …}를 생성한다. 다음으로 사전 훈련된 LAS 모델을 사용하여 TTS 데이터에 대한 디코딩을 수행한다. 각 TTS 발화 ui는 빔 검색 디코딩 후 N 가설 {Hi1, Hi2, …, HiN}과 쌍을 이룰 수 있다. N-best 목록의 모든 가설을 사용하여 훈련 데이터를 생성함으로써 LAS 모델의 기본 오류 분포의 더 많은 분산을 포착하는 다양한 훈련 세트를 만든다. SC 훈련 중에 LAS의 n-best 목록에서 가설 Hij를 무작위로 샘플링하고 이를 ground truth transcript yi와 결합하여 훈련 쌍을 형성한다.
#### 3.3.2. Architecture and training
우리는 [21]의 신경 기계 번역 모델과 유사한 맞춤법 교정기를 위해 attention 기반 인코더-디코더 sequence-to-sequence 아키텍처를 사용한다. 입력 및 출력 문장은 먼저 단어 조각으로 디코딩된다[22]. 인코더는 입력 시퀀스 Hij으로 훈련한 임베딩을 가져와서 양방향 LSTM 계층 스택을 통해 상위 수준 표현에 매핑한다. 디코더는 또한 attention 매커니즘을 사용하여 인코더 표현을 처리하고 출력 시퀀스 yi를한번에 하나씩 생성하는 스택된 단방향 LSTM 레이어로 구성된다. Figure 1은 모델 아키텍처를 보여준다. 표준 attention 기반 sequence-to-sequence 모델과 비교하면 몇 가지 차이점이 있다. 첫째, 인코더와 디코더의 레이어간에 잔여 연결이 추가된다. 각 LSTM 셀 내에서 게이트 별 레이어 정규화가 적용되고 multi-head additive attention이 사용된다. 하단 디코더 계층과 최종 인코더 계층 출력은 모든 디코더 LSTM 계층과 연결을 통해 소프트 맥스 계층에 제공되는 순환 attention 컨텍스트를 얻는 데 사용된다. 이 모델은 standard maximum-likelihood criterion을 사용하여 훈련되어 해당 입력이 주어진 경우 실제 출력의 로그 확률 합계를 최대화한다.

여기서 λ(람다)는 held-out 세트에서 결정된 interpolation(보간) 가중치이다.
#### 3.3.3. Inference
추론하는 동안 빔 serach로 LAS 모델을 디코딩하는 것은 발화 u를 가지고 해당 로그 확률 점수 {p1,p2,…,pN}가 있는 N 개의 가설 {H1,H2,…,HN}이 생성된다. 가설 Hi의 경우 SC 모델을 유사하게 사용하여 해당 로그 확률 점수 {qi1,qi2,…,qiM}와 함께 M 개의 새로운 가설 {Ai1,Ai2,…,AiM}을 생성할 수 있다. 따라서 주어진 발화 u에 대해 계단식 LAS 및 SC 모델은 연관된 점수와 함께 총 N × M 가설을 생성할 수 있다. 모든 N × M 후보를 LM으로 재 채점하면 일련의 LM 점수 {r11,r12,…,rMN}가 제공된다. 마지막으로 다음 기준을 사용하여 가장 가능성이 높은 가설을 찾을 수 있다.

여기서 λLAS, λSC 및 λLM은 각각 held-out 세트에서 결정되는 LAS, SC 및 LM 점수에 대한 가중치이다. SC 모델을 사용하여 N 개의 LAS 가설을 각각 독립적으로 수정하면 시스템의 총 계산 비용이 N 배 증가한다. 다음 실험 섹션에서는 SC 모델이 최상위 LAS 가설만 수정하는데 사용되는 구성 (즉, N = 1 사용)을 전체 N × M 구성으로 비교한다.
4. EXPERIMENTAL SETUP
LibriSpeech [23]에 대한 실험을 수행한다. 훈련 데이터에는 읽기 오디오 북 녹음에서 약 960 시간의 음성이 포함된다. 우리는 각각 약 5.4 시간의 음성이 포함된 “깨끗한”개발 및 테스트 세트를 평가한다. 특성 추출을 위해 80 차원 log-mel 필터 뱅크 특성은 델타 및 가속도와 함께 10ms만큼 이동 한 25ms 창에서 계산된다. 외부 텍스트 전용 훈련 데이터 세트로 우리는 개발 및 테스트 세트의 텍스트와 겹치지 않도록 신중하게 선택한 800M개 단어 LibriSpeech 언어 모델링 코퍼스를 사용한다. 단일 문자 단어 만 포함하거나 90 단어보다 긴 0.5M 시퀀스를 필터링하여 코퍼스를 사전 처리한다. 나머지 40M 텍스트 시퀀스를 사용하여 언어 모델을 교육하고, TTS 데이터 세트를 생성하여 LAS 모델을 교육하고, 오류 가설을 생성하여 SC 모델을 교육한다.
4.1. Speech recognition model
기본 LAS 인식 모델은 인코더에서 2 개의 컨볼 루션 레이어와 3 개의 양방향 LSTM 레이어를 사용하고 디코더에서 단일 단방향 LSTM 레이어를 사용한다. 헤드가 4개인 multi-headed additive attention 매커니즘이 사용된다. 우리는 바이트 쌍 인코딩 알고리즘을 사용하여 생성 된 16K개 토큰이 있는 워드 피스 모델을 사용한다. 단어 조각은 나머지 모델과 함께 훈련되는 96 차원 임베딩으로 표시된다. 정규화를 위해 라벨 스무딩 [6]은 각 출력 단계에서 Ground Truth 토큰의 무게를 0.9로 측정하고 나머지 확률 질량을 다른 토큰에 균일하게 분배하여 적용한다. 추론하는 동안 우리는 빔 크기가 8 인 빔 검색 디코딩을 사용한다. 기준 LAS 모델은 16 명의 작업자가 있는 비동기 확률 적 경사 하강법 최적화(asynchronous stochastic gradient descent optimization)를 사용하여 훈련된다. 모든 모델은 Tensorflow [24]에서 구현되고 Adam 최적화 도구 [25]를 사용하여 훈련된다.
4.2. Language model
우리는 외부 언어 모델로 사용하기 위해 두 개의 단방향 LSTM 레이어로 스택 RNN을 훈련한다. 동일한 16K개의 워드 피스 토큰 세트가 LAS 모델로 사용된다. 훈련 중 조기 중지는 개발 세트의 난이도를 기반으로 한다. [1]과 유사하게 LM을 사용하여 빔 검색으로 LAS 모델을 디코딩하여 생성된 n-best 목록을 다시 채점한다. 보간 가중치 λ는 held-out dev set (development set)에서 스윕된다??? The interpolation weight λ is swept on a held-out dev set.
** *홀드 아웃은 데이터 세트를 ‘train’및 ‘test’세트로 분할하는 것이다. 훈련 세트는 모델이 훈련된 대상이며 테스트 세트는 모델이 보이지 않는 데이터에서 얼마나 잘 수행되는지 확인하는 데 사용된다.
4.3. TTS model
음성을 합성하기 위해 본 논문에서는 고 fidelity(충실도) 음성을 매우 효율적으로 생성 할 수 있는 Parallel WaveNet 모델 [19]을 사용한다.이 모델은 한 명의 여성 화자로부터 65 시간의 음성 훈련을 받았다. 이 모델을 사용하여 전체 텍스트 전용 데이터 세트에 대한 추론을 수행하고 40M개 오디오 발화를 생성한다. 이러한 합성 음성 발화를 960 시간 LibriSpeech 훈련 세트와 결합하여 결합된 real + TTS LAS 인식기를 훈련한다. 훈련 중에 각 batch는 70 % 실제 음성과 30 % 합성 음성으로 구성된다.
4.4. Spelling correction model
제안된 SC모델은 인코더에서 3개의 양방향 LSTM 레이어를 사용하고 디코더에서 3개의 단방향 LSTM 레이어를 사용한다. 인코더와 디코더의 세 번째 레이어에 잔여 연결이 추가된다. 4-headed 추가 attention이 사용된다. LAS 및 언어 모델에서와 동일한 16K 워드 피스 모델이 채택되었다. 빔 서치 디코딩은 빔 크기 8로 수행된다. 정규화를 위해 0.2의 드롭 아웃 비율이 임베딩 레이어와 각 LSTM 레이어 출력 모두에 적용된다. Attention 드롭 아웃도 같은 비율로 적용된다. 불확실성이 0.1인 균일한 레이블 평활화가 적용되고 매개 변수는 가중치 10의-5제곱으로 L2 정규화된다. 학습률 일정에는 초기 선형 워밍업 단계, 일정 단계 및 이후의 지수 감쇠 단계가 포함된다 [21]. SC모델은 32 GPU를 사용하는 동기식 훈련으로 훈련되고 적응 형 그래디언트 클리핑은 훈련을 더욱 안정화하는데 사용된다. 이 모델에 대한 훈련 데이터를 생성하기 위해 먼저 baseline LAS 모델을 사용하여 40M개 깨끗한 TTS 발화를 디코딩한다. 각 TTS 발화는 8개의 가설을 생성하고 각 가설은 해당 ground truth transcript와 그룹화되어 SC 훈련 쌍을 형성한다. 이 프로세스는 총 약 3 억 2 천만 쌍의 훈련 쌍을 생성한다.
추가로 room 시뮬레이터를 사용하여 추가 노이즈 및 잔향으로 합성된 발화를 손상시켜 증강 데이터 세트를 사용하는 다중 스타일 훈련 (MTR) 구성을 추가로 실험한다. 소음신호는 유튜브와 일상 생활에서 시끄러운 환경녹음으로부터 수집되며 전체 SNR이 20dB에서 40dB 사이가되도록 무작위로 반향되고 음성과 혼합된다[26]. 이 프로세스를 통해 이 프로세스를 통해 전체 합성된 음성 세트에서 총 4 천만(40M) 개의 시끄러운 발화가 발생한다. 이러한 발화는 잡음이 있는 SC훈련 세트를 생성하기 위해 위에서 설명한 동일한 절차에 따라 기준 LAS 모델에 의해 디코딩된다. 깨끗하고 시끄러운 훈련 세트의 조합은 총 640M MTR 쌍을 생성한다.
5. RESULTS
이 섹션에서는 텍스트 전용 데이터를 통합하는 다양한 방법을 비교한다.
외부 LM을 사용하여 n-best 목록을 다시 채점하지 않고 LAS 모델을 사용하여 찾은 기준 결과는 표 1의 상단에 표시된다. (상위 2 개 행). 표 1의 5 행에서 볼 수 있듯이 상위 가설을 수정하면 기준선에 비해 15.8 %의 상대적 개선이 이루어진다. 개발 세트를 조정하여 λ = 0.5의 최적 LM 가중치를 선택했다. LM rescoring은 LAS 기준선에 비해 21.7 %의 상대적 개선을 가져온다. 다음으로 텍스트 전용 훈련 데이터에서 합성된 음성을 사용하여 LAS 훈련 세트를 확대하여 결과를 제시한다. 4.3 절에서 언급했듯이 과적 합을 피하기 위해 LAS-TTS라고하는 실제 오디오와 TTS 오디오의 조합을 사용하여 LAS 모델을 훈련한다. 표 1은 이것이 성능을 약간 향상시키는 것을 보여주지만 이득은 기준선을 다시 채점하는 LM만큼 크지 않다. 그러나 TTS 강화 교육과 LM 채점의 조합은 LM 채점보다 향상되어 두 방법의 상보성을 보여준다.
5.1. SC model
먼저 인식자가 출력 한 최상위 가설만을 고려할 때 SC 방법의 성능을 계산한다. 표 1의 5 행에서 볼 수 있듯이 상위 가설을 수정하면 기준선에 비해 15.8 %의 상대적 개선이 이루어진다.
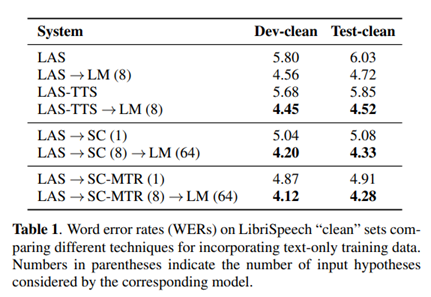

그림2는 SC모델에서 사용하는 attention 가중치의 예시를 보여준다. Attention 가중치가 일반적으로 단조롭고 오류가 발생하는 경우 attention 가중치가 인접한 컨텍스트에 정렬되어 모델이 더 적합한 출력을 선택하는데 도움이 된다. 이 동작은 그림 2의 출력 토큰 10 ~ 15 사이에서 볼 수 있다.
5.1.1. Generating richer n-best lists

표 2는 철자 교정이 있는 경우와 없는 경우 LAS 모델의 Oracle WER를 비교한다.
** oracle WER:* 오라클 WER은 생성된 격자에 저장된 경로의 WER을 의미하며 점수에 관계없이 발화와 가장 잘 일치한다. 즉, oracle WER는 주어진 격자에서 점수를 조정하여 얼마나 잘 얻을 수 있는지에 대한 경계를 제공한다.
SC 모델의 두 가지 구성이 고려된다. LAS 모델에서 내보낸 최상위 가설을 수정하여 최종 8개 후보 목록을 만들고 LAS n-best 목록의 8 개 항목을 모두 수정하여 64 개 후보 목록으로 확장한다.
상위 LAS 가설만 수정할 때 SC 모델은 Oracle WER에서 약간의 개선만 이루어진다. 그러나 SC 모델을 전체 LAS n-best 목록의 각 항목에 독립적으로 적용하면 oracle WER가 거의 절반으로 크게 감소한다. 이는 SC 모델이 더 풍부하고 현실적인 가설 목록을 생성할 수 있음을 보여주며, 이는 정확한 transcript를 포함할 가능성이 더 높다.
이것은 3.3.3 절에 소개 된 확장 된 n-best 목록에서 LM 채점을 사용하도록 동기를 부여한다. dev set에서 튜닝하여 찾은 최적의 가중치는 λLAS = 0.7, λSC = 1.0 및 λLM = 0.1이다. 테스트 세트에서 동일한 매개 변수를 사용한다. 표 1의 6 행에서 볼 수 있듯 이는 SC 모델을 단독으로 사용하는 것에 비해 상당한 성능 향상을 가져오며, 이는 기준선 LAS 모델 단독에 비해 28 % 이상의 상대적 개선에 해당한다. 이 유망한 결과는 세 모델 각각에서 내보낸 확률 점수가 서로 보완적이라는 것을 보여준다.
#### 5.1.2. Train on more realistic TTS dataset
TTS 데이터를 사용하여 LAS 모델이 만드는 오류를 합성하는 것은 TTS 데이터와 실제 오디오가 일치하지 않기 때문에 완벽하지 않다. 따라서 TTS 데이터와 실제 오디오 데이터에서 디코딩된 오류를 비교하면 표 3과 같이 여전히 큰 불일치가 있다. 특히 이 표는 LibriSpeech 개발 세트 및 동일한 transcript를 사용하여 생성된 TTS dev set에 대한 LAS 모델의 성능을 보여준다. TTS 테스트 세트에 적용된 SC 모델은 LM 채점 후에도 실제 오디오 테스트 세트보다 성능이 뛰어나다. 이 오디오 불일치 문제를 해결하기 위해 TTS 데이터에 노이즈를 추가하여 사운드를 덜 “명확”하게 만들고 노이즈가 더 많은 n-best 목록을 만들려고 한다. 표 1의 마지막 두 행은 MTR TTS 데이터에서 디코딩 된 오류에 대해 훈련된 SC 모델의 결과를 요약한다. MTR 데이터가 있는 SC 모델의 성능은 깨끗한 데이터보다 향상된다. 전반적으로 MTR-ed SC 모델에 LM 채점을 적용한 후 LAS 기준선에 비해 29.0 %의 상대적 개선을 달성했다.

5.2. Error analysis
철자 교정 전후에 LM 재 점수를 사용하는 LAS 모델의 오류를 이해하기 위해 몇 가지 대표적인 예를 가져왔다. 표 4는 “LAS + SC + LM rescore”시스템이 “LAS + LM rescore”시스템보다 우세한 예를 보여준다. 예제는 SC 모델이 고유 명사 및 희귀 단어의 많은 오류를 수정하고 일부 시제 및 문법 오류를 수정 함을 보여준다.

6. CONCLUSIONS
본 논문에서는 음성 인식기에 의해 만들어진 오류를 명시적으로 수정하도록 훈련된 철자 수정 모델을 제안한다. SC 모델을 훈련하기 위해 우리는 큰 텍스트 전용 말뭉치에서 합성된 TTS 데이터를 디코딩하여 오류 가설을 생성한다. 여기서 결과는 SC 모델이 최상위 LAS 가설을 직접 수정할 때 기준선 LAS 모델에 비해 분명한 개선을 가져온다는 것을 보여준다. LAS n-best 목록의 모든 항목을 수정함으로써 SC 모델은 Oracle WER가 상당히 낮은 확장 목록을 생성 할 수 있다. 확장 된 n-best 목록을 외부 LM으로 추가 채점 할 때 TTS 데이터에 대한 간단한 LM 채점 및 직접 LAS 모델 훈련보다 성능이 뛰어나다. TTS 데이터와 실제 오디오 간의 불일치를 완화하여 추가 개선을 위해 MTR TTS 데이터에 대한 SC 모델을 훈련한다. MTR 데이터가 있는 SC 모델의 성능은 깨끗한 데이터보다 분명히 향상된다.
댓글남기기