
Towards end-to-end speech recognition
Bo Li, Yanzhang He, Shuo-Yiin Chang ISCSLP(International Symposium on Chinese Spoken Language Processing) Tutorial 4 Nov. 26, 2018
1. intro
최근 음성합성(speech synthesis)분야는 상당한 수준까지 올라왔다. Google의 Tacotron2가 성공적인 예 중 하나이고 네이버의 클로바는 배우 유인나의 목소리를 낼 수 있다.
그와 달리 음성인식은 왜 아직 정복되지 않았을까? 결론부터 말하자면 음성인식은 아직은 갈 길이 멀다. 일단 음성인식은 여러 논문에서 LibriSpeech나 WSJ, TIMIT등의 데이터를 기반으로 최첨단 (SOTA, state of the art)이라고 주장하지만 이는 단순히 모델을 평가하기 위한 기준일 뿐 실제 서비스를 논할 수 있는 지표는 아니다. 대부분의 모델로는 SOTA를 찍는 게 쉽지 않고 실제로 페이퍼를 통해 공개된 사례가 없다. 실제 서비스화 과정에서 end-to-end 시스템을 가능하게 하려면 노이즈 제어가 기본적으로 필요하며 화자 구분과 음성 추출까지 정확하게 이루어져야 한다.(지역적인 방언이나 특유의 억양까지도) 그래서 언어모델 등의 후처리 기법이나 다른 방법들이 필요하다. 하나의 예로 “물냉면”을 주문했는데 “밀냉면”이 온다면 황당하지 않을까? 극단적인 예로 볼 수 있지만 음성인식에서 정확도는 상당히 중요하다.
2. What is End-to-End ASR?
전통적인 음성인식의 pipeline은 다음과 같다.

전통적인 ASR에서 대부분 음향, 발음 및 언어 모델이 구성 요소로 포함되며 각각의 모델은 별도로 훈련된다.

전통적인 ASR시스템과 달리 End-to-End ASR(Automatic Speech Recognition)은 입력 음성 특징을 자소 또는 단어로 직접 매핑하는 시스템이다. 전통적인 파이프라인을 단순화하고 최종 평가 지표(일반적으로 단어 오류율, WER)와 관련해 최적화하도록 훈련된다.

입력되는 음성의 특징을 추출하고 Acoustic model을 통하고 decoder에서 언어모델 등이 후처리를 진행한다.
이런 pipeline을 기반으로 End-to-End ASR을 서비스하기 위해 여러가지 방식이 제시되었고 크게
-
CTC(Connectionist Temporal Classification)
-
Attention-based Encoder-Decoder Models
-
Online Model
로 구분할 수 있다.
1) Connectionist Temporal Classification
제일 먼저 등장한 것은 CTC(Connectionist Temporal Classification) (2006) 인데 오래된 모델인 만큼 유명하다. CTC의 컨셉은 다음과 같다.
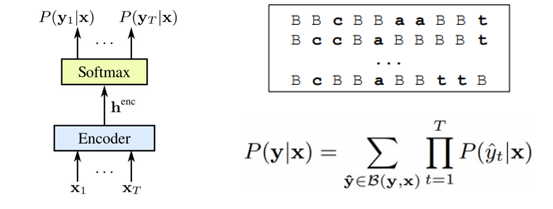
Encoder는 Uni 혹은 Bi directional RNN(혹은 LSTM)이 여러 계층으로 구성되어 있고 Encoder로 들어온 입력 데이터는 최종적으로 Softmax를 통과해서 출력된다.
이후에 이러한 CTC를 기반으로 End-to-End ASR (2014)이 제안되었는데 이 논문에서는 character-based CTC를 사용해서 단어를 추론하고 더 좋은 성능을 내기 위해서 후처리로 언어모델이 사용한다. CTC 기법을 적용해 뛰어난 성능을 기록한 아키텍처는 바이두(Baidu)에서 2015년 발표한 Deep Speech2가 있다. Deep Speech의 경우 n-gram 기반의 KenLM을 사용한다.
2) Attention-based Encoder-Decoder Models
CTC와 비슷한 시기에 Listen, Attend and Spell(LAS)(2015)을 Google Brain에서 제안했는데, 이때부터 ASR은 크게 CTC와 LAS로 나뉜다고 할 수 있다. LAS의 개념은 다음과 같이 표현할 수 있다.

크게 3가지 구성요소가 있다. 첫번째는 음성 입력을 히든 벡터로 변환하는 인코더(encoder)인데 이를 Listener 모듈이라고도 한다. 두번째는 어텐션(attention) 모듈이다. 디코더 출력시 인코더 입력의 어떤 정보에 집중해야 할지 알려주는 역할을 한다. 마지막으로 타겟 시퀀스를 생성하는 디코더(decoder), Speller이다. 세 모듈은 각각 기존 음성 인식 시스템에서 음향모델(Acoustic Model), 음성-음소 간 얼라인먼트 모델(Alignment Model), 언어모델(Language Model)이 하는 역할과 유사하다고 볼 수 있다.
CTC와 LAS는 요즘 논문에서도 자주 인용되는 인기 있는 모델이지만 이 자체만으로는 실시간 스트리밍에 적합하지 않다. 전체 문장을 입력으로 넣고 처리하는 구조에서 발생하는 여러 한계를 보안하기위해 Online model이 등장했다.
3) Online Models
Online Model은 스트리밍 음성을 처리할 수 있도록 구조적으로 설계된 모델인데 대표적으로 RNN-Transducer, NT, MoChA가 있다. 특히 대표적인 Online model인 RNN-Transducer는 구글에서 발표한 STREAMING END-TO-END SPEECH RECOGNITION FOR MOBILE DEVICES (2018)로 다시 주목받았다.
RNN-Transducer (Recurrent Neural Network Transducer)
Recurrent Neural Network Transducer는 RNN 기반의 언어모델(Language Model)에 CTC loss를 적용한 모델이다. 음성 입력이 들어오는 중간에도 예측이 가능한, 실시간 음성 인식 모델로 그 구조는 다음과 같다.
이는 기존 CTC 모델과의 차이를 보여주는 그림인데, Encoder에 Prediction Network를 연결해서 사용한다. prediction network를 연결시켜 줌으로써 후처리 언어모델의 효과를 얻을 수 있다.
흥미로운 사실은 CTC-based를 제안했던 저자들이 Online Models을 새롭게 제시하고 있다는 사실이다.(Graves는 RNN-Transducer를, Jaitly는 NT를 각각 제안) 아래 바이두 논문(2017)에 따르면 CTC나 LAS 모델과 비교해서 RNN-Transducer의 인식률이 결코 밀리지 않는다는 주장을 하고 있다.

하지만 아직 명확하게 LibriSpeech나 WSJ같은 동일한 데이터를 기준으로 SOTA를 증명해낸 내용은 찾기 어렵다. 이후에도 CTC나 LAS의 변형과 새로운 모델도 마찬가지이다.
Baidu에서 2017년 발표한 논문에서 보인 세 기법 간의 차이를 나타낸 그림

현대에 와서는 기존에 제시된 모델의 hierarchies에 변화를 주거나 새롭게 제안되는 기법들(예를 들면 SpecAugment)을 잘 다룰 수 있는 능력이 필요하다. 기존 모델들을 이해하고 새로운 것과 연동시킬 수 있는 언어적 스킬도 중요하다.
Reference
[1] http://iscslp2018.org/images/T4_Towards%20end-to-end%20speech%20recognition.pdf
[2] https://web.stanford.edu/~jurafsky/slp3/9.pdf
[3] https://ratsgo.github.io/speechbook/docs/decoding#end-to-end-model
[4] https://jybaek.tistory.com/793
댓글남기기