
Deep Speech: Scaling up end-to-end speech recognition
Awni Hannun∗ , Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, Andrew Y. Ng Baidu Research – Silicon Valley AI Lab
Abstract
이 논문에서는 End-to-end deep learning을 사용하여 개발된 최첨단 음성 인식 시스템을 소개한다.
복잡한 처리 파이프라인에 의존하는 전통적인 음성 시스템보다 훨씬 간단한 구조를 가지고 있다.
또 기존 시스템은 시끄러운 환경에서 사용할 때 성능이 저하되는 경향이 있는데, 이 시스템은 배경의 소음, 잔향 또는 화자의 변화를 모델링하기 위해 hand-designed component를 사용하지 않고 대신 이러한 효과에 대응하는 기능을 직접 학습한다. “음소” 라는 개념도 없기 때문에 음소 사전이 필요하지 않다. 이 접근방식의 핵심은 최적화된 여러 GPU를 사용하는 RNN 훈련 시스템과 학습을 위해 많은 양의 다양한 데이터를 효율적으로 얻을 수 있는 일련의 새로운 데이터 합성 기술이다. Deep Speech는 많은 분야에서 연구된 Switchboard Hub5’00에서 이전에 발표된 결과를 능가하여 전체 테스트 셋에서 16.0 % 오류를 달성했습니다. 또한 널리 사용되는 최첨단 상용 음성 시스템보다 시끄러운 환경에서 음성을 더 잘 처리한다.
*end-to-end deep learning: 처음부터 끝까지라는 의미로 데이터(입력)에서 목표한 결과(출력)를 사람이 개입 없이 얻는다는 뜻을 담고 있다.
1. Introduction
최고의 음성 인식 시스템은 여러 알고리즘과 수작업 설계 처리 단계로 구성된 정교한 파이프 라인에 의존한다. 이 논문에서는 Deep Speech라는 end-to-end 음성 시스템을 소개한다. 이는 수작업의 처리단계를 딥러닝이 대체하는 것을 말한다. 언어 모델과 결합된 이 접근방식은 어려운 음성 인식 작업에서 기존 방법보다 더 놓은 성능을 보이며 훨씬 간단하다. 이러한 결과는 여러 GPU와 수천 시간의 데이터를 사용하여 대규모 RNN (Recurrent Neural Network)을 훈련함으로써 가능하다. 시스템은 데이터에서 직접 학습하므로 스피커 적응 또는 노이즈 필터링을 위한 특수 구성 요소가 필요하지 않다. (사실, 화자 변화 및 소음에 대한 견고성이 중요한 설정에서 이 시스템은 탁월하다.) Deep Speech는 Switchboard Hub5’00 corpus에서 이전에 게시된 방법보다 성능이 우수하며 16.0 %의 오류를 달성하였다. 또 소음이 있는 음성 인식 테스트에서 상용 시스템보다 우수한 성능을 발휘한다.
전통적인 음성 시스템은 특화된 입력 기능, 음향 모델 및 HMM (Hidden Markov Model)을 포함하여 고도의 처리 단계를 많이 사용한다. 이러한 파이프 라인을 개선하려면 전문가가 기능과 모델을 조정하는 데 많은 노력을 기울여야한다. 딥 러닝 알고리즘의 도입은 일반적으로 음향 모델을 개선하여 음성 시스템 성능을 향상시켰다. 이러한 개선은 중요하지만 딥러닝은 여전히 전통적인 음성 파이프 라인에서 제한된 역할을 한다. 결과적으로 시끄러운 환경에서 음성인식과 같은 성능을 향상시키려면 견고성을 위해 나머지 시스템 부분을 힘들게 설계해야 한다. 대조적으로 이 시스템은 RNN을 사용하여 end-to-end deep learning을 적용한다. 대규모 데이터 세트에서 학습하여 전반적인 성능을 향상시킨다. 이 모델은 transcription을 생성하기 위해 end-to end 학습을 했기 때문에 충분한 데이터와 컴퓨팅 성능을 통해 자체적으로 소음이나 화자 변형에 대한 견고성을 학습할 수 있다.
그러나 end-to-end deep learning의 이점을 활용하는데 몇 가지 문제가 있다.
1) 레이블된 대규모 훈련 세트를 구축하는 혁신적인 방법을 찾아야한다. 2) 모든 데이터를 효과적으로 활용하기에 충분히 큰 네트워크를 훈련할 수 있어야한다.
음성 시스템에서 레이블된 데이터를 처리하기위한 한 가지 과제는 입력 음성과 텍스트 대본의 정렬을 찾는 것인데 이러한 문제는 [13] A. Graves, S. Fernandez, F. Gomez, and J. Schmidhuber. Connectionist temporal classification: ´ Labelling unsegmented sequence data with recurrent neural networks. In ICML, pages 369– 376. ACM, 20 이 논문에서 다루었으며 신경망이 훈련 중에 정렬되지 않은 오디오를 쉽게 사용할 수 있다.
한편, 아래의 논문은 대규모 신경망에서의 빠른 훈련을 다루고 있는데, 다중 GPU 계산의 속도 이점을 보여준다. [7] A. Coates, B. Huval, T. Wang, D. J. Wu, A. Y. Ng, and B. Catanzaro. Deep learning with COTS HPC. In International Conference on Machine Learning, 2013. 이 논문에서는 이러한 통찰력을 활용해 대규모 음성 데이터 세트 및 확장 가능한 RNN 학습을 기반으로 복잡한 기존 방법을 능가할 수 있는 일반 학습 시스템을 달성하는 것을 목표로 한다. 부분적으로 아래의 논문에서 영감을 받았으며 수작업을 대체하기 위해 초기 비지도 학습 기술을 적용했다.
[27] H. Lee, P. Pham, Y. Largman, and A. Y. Ng. Unsupervised feature learning for audio classification using convolutional deep belief networks. In Advances in Neural Information Processing Systems, pages 1096–1104, 2009 GPU에 잘 매핑하기 위해 특별히 RNN 모델을 선택했으며 병렬화를 개선하기 위해 새로운 모델 파티션 체계를 사용한다. 또한 시스템에서 왜곡된 대량의 레이블된 음성 데이터를 조립하는 프로세스를 제안한다. 수집 및 합성된 데이터의 조합을 사용하여 시스템은 사실적인 소음과 화자 변화에 대한 견고함을 학습한다. (Lombard effect 포함.)
이러한 아이디어를 종합하면 기존 파이프 라인보다 한 번에 더 간단하면서도 어려운 음성 작업에서 더 나은 성능을 발휘하는 end-to-end speech system을 구축하는 데 충분하다. Deep Speech는 full Switchboard Hub5’00 테스트 셋에서 16.0%의 오류율을 달성한다. (게시된 것들 중 가장 좋은 결과) 또한 자체 구성한 시끄러운 환경에서의 음성 인식 데이터 셋에서 19.1%의 word error rate를 달성했다. (최고의 상용 시스템이 30.5 %의 word error rate)
2. RNN Training Setup – 모델과 훈련 프레임워크에 대한 설명

2.1 Regularization
RNN의 분산을 더 줄이기 위해 몇 가지 기술을 사용한다. 훈련 중에 드롭 아웃[19]을 5 %-10 % 사이로 설정한다. Feed forward 레이어에는 드롭 아웃을 적용하지만 recurrent hidden activations에는 적용하지 않는다. (네트워크 평가 중 컴퓨터 비전에서 일반적으로 사용되는 기술은 변환 또는 반사에 의해 입력을 무작위로 지터하고, 결과를 투표하거나 평균하는 것이다.)[23] 지터링은 음성인식에서 일반적인 방법은 아니지만 원본 오디오 파일을 왼쪽과 오른쪽으로 5ms만큼 변환한 다음 재계산 후 순방향 전파하고 출력 확률의 평균을 구하는 것이 좋다는 것을 알았다.
테스트에서는 여러 RNN의 앙상블을 사용하여 동일한 방식으로 출력의 평균을 구한다.
Dropout은 인공 신경망의 각 레이어 노드에서 학습할 때 마다 일부 노드를 사용하지 않고 학습을 진행한다. 최종적으로 인공 신경망으로도 과적합을 방지해주며 실제 테스트에서도 좋은 성능을 보여준다.
[19] G. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. abs/1406.7806, 2014. http://arxiv.org/abs/1406.7806.
[23] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106–1114, 2012.
2.2 Language Model
대량의 레이블된 음성 데이터에서 학습하면 RNN 모델은 읽을 수 있는 문자 수준의 transcription을 생성하는 방법을 배울 수 있다. (실제로 RNN에 의해 예측되는 가장 가능성 있는 문자열은 거의 정확하다. – 외부 언어 제약없이) RNN에 의해 만들어진 오류는 영어 단어의 음성학적으로 그럴듯한 표현인 경향이 있으며 피하기 어렵다.

모든 단어나 언어 구조를 듣기 위해 충분한 음성 데이터로 훈련하는 것은 비현실적이기 때문에 이 시스템은 N-gram 언어 모델과 통합하여 레이블이 없는 거대한 텍스트 말뭉치에서 쉽게 학습 할 수 있도록 한다. 비교를 위해 우리의 음성 데이터 세트에는 일반적으로 최대 3 백만 개의 발화가 포함되지만 섹션 5.2의 실험에 사용된 N-gram 언어 모델은 2 억 2 천만 구문의 말뭉치에서 훈련되어 495,000 단어의 어휘를 지원한다.
RNN의 출력이 주어지면 문자의 시퀀스를 찾기 위해 검색을 수행한다. c1, c2 …는 RNN 출력과 언어 모델 (언어 모델이 문자열을 단어로 해석)에 따라 가장 가능성이 높다. 특히 결합된 Q(c)를 최대화하는 시퀀스 c를 찾는 것을 목표로 한다.
| $P(c | x) $: RNN의 출력 |
$c_1, c_2, \cdots $: 문자 시퀀스
\[Q(C) = log(P(c|x))+\alpha log(P_{lm}(c)) + \beta word_count(c)\]여기서 α와 β는 RNN, 언어 모델 제약 조건 및 문장 길이 사이의 균형을 제어하는 조정 가능한 매개 변수 (교차 검증으로 설정)이다.
Hannun 등이 설명한 접근 방식과 유사한 1000-8000 범위의 일반적인 빔 크기로 고도로 최적화된 빔 검색 알고리즘을 사용하여 목표를 최대화한다.[16].
[16] A. Y. Hannun, A. L. Maas, D. Jurafsky, and A. Y. Ng. First-pass large vocabulary continuous speech recognition using bi-directional recurrent DNNs. abs/1408.2873, 2014. http://arxiv.org/abs/1408.2873.
3. Optimizations - gpu 최적화
이 논문에서는 네트워크를 고속 실행 (따라서 빠른 교육)할 수 있도록 몇 가지 설계를 했다. 예를 들어 구현이 간단하고 고도로 최적화된 몇 가지 BLAS 호출에만 의존하는 homogeneous 정류 선형 네트워크를 선택했다. 중요한. 실험 속도를 높이기 위해 다중 GPU 학습 [7, 23]을 사용하지만 이를 효과적으로 수행하려면 몇 가지 추가 작업이 필요하다.
3.1 Data parallelism - 데이터 병렬 처리
데이터를 효율적으로 처리하기 위해 두 가지 수준의 데이터 병렬 처리를 사용한다.
1) 각 GPU는 많은 예제를 병렬로 처리한다.
이것은 일반적으로 많은 예제를 단일 행렬로 연결하는 방법으로 수행된다.
예를 들어, 순환 계층에서 단일 행렬 벡터 곱셈 $W_rh_t$를 수행하는 대신 $W_rH_t\ where \ H_t=[h_t^{(i)}, h_t^{(i+1)}, \cdots]$를 계산하여 병렬로 많은 작업을 수행하는 것을 선호한다.
$h_t^{(i)}$ : 시간 $t$에서 $i$ 번째 예 $x(i)$에 해당
GPU는 Ht가 비교적 넓을 때 (예 : 1000 개 이상의 예제) 가장 효율적이므로 가능한 한 GPU 하나에서 많은 예제를 처리하는 것을 선호한다 (최대 GPU 메모리 제한).
(단일 GPU가 자체적으로 지원할 수 있는 것보다 더 큰 미니 배치를 사용하려면 여러 GPU에서 데이터 병렬 처리를 사용한다.) 각 GPU는 별도의 예제 미니 배치를 처리한 다음 각 반복 중에 계산된 기울기들을 결합한다. 일반적으로 GPU에서 2 배 또는 4 배 데이터 병렬 처리를 사용한다.
그러나 발화의 길이가 단일 행렬 곱셈으로 결합될 수 없기 때문에 데이터 병렬 처리가 쉽게 구현되지 않는다. 훈련 예제를 길이별로 정렬하고 비슷한 크기의 발화를 미니 배치로 결합하고 필요할 때 침묵으로 패딩하여 배치의 모든 발화가 동일한 길이를 갖도록 해 문제를 해결한다.
3.2 Model parallelism - 모델 병렬 처리
데이터 병렬 처리는 미니 배치 크기의 적당한 배수 (예 : 2 ~ 4)에 대한 훈련 속도를 향상 시키지만, 더 많은 예제를 단일 기울기 업데이트로 일괄 처리하면 학습의 수렴률을 개선하지 못해 결과가 감소한다. 즉, 2 배 많은 GPU에서 2 배 많은 예제를 처리하면 훈련 속도가 2 배 향상되지 않는다는 것을 말한다.
예제를 GPU 수의 2 배로 분산시킨다. 각 GPU 내의 미니 배치가 축소됨에 따라 대부분의 작업은 메모리 대역폭이 제한된다. 더 확장하기 위해 모델을 분할하여 병렬화한다. (“모델 병렬 처리”[7, 10]).
이 모델은 순환 계층의 순차적인 특성으로 인해 병렬화를 시도한다. 양방향 계층은 순방향 계산과 독립적인 역방향 계산으로 구성되어 있으므로 두 계산을 병렬로 수행할 수 있다. 하지만 h (f)와 h (b)를 별도의 GPU에 배치하기 위해 RNN을 분할하면 h (5)를 계산할 때 상당한 데이터 전송이 발생한다. 따라서 우리는 모델에 대한 의사 소통이 덜 필요한 다른 작업 분할을 선택했다. 간 차원을 따라 모델을 반으로 나눈다. 순환계층을 제외한 모든 레이어는 시간에 따라 나눠질 있다. t = 1에서 t = T (i) / 2까지, 하나의 GPU에 할당되고 나머지 절반은 다른 GPU에 할당된다. 복 계층 활성화를 계산할 때 첫 번째 GPU는 순방향 활성화 h (f)를 계산하기 시작하고 두 번째 GPU는 역방향 활성화 h (b)를 계산하기 시작한다. 중간 지점 (t = T (i) / 2)에서 계산할 때 두 GPU는 중간 활성화, h (f) T / 2 및 h (b) T / 2를 교환한다. 그런 다음 첫 번째 GPU는 h (b)의 역방향 계산을 완료하고 두 번째 GPU는 h (f)의 순방향 계산을 완료한다.
3.3 Striding
순환 계층은 병렬화가 가장 어렵기 때문에 실행 시간을 최소화하기 위해 노력했다. 원래 입력에서 크기 2의 “단계”(또는 stride)을 취하여 반복 레이어를 줄여서 RNN이 절반의 단계를 갖도록한다. 이것은 첫 번째 레이어에서 스텝 크기가 2인 합성곱 신경망[25]와 유사하다. 우리는 cuDNN 라이브러리 [2]를 사용하여 첫 번째 컨볼루션 레이어를 효율적으로 구현한다.
4. Training data – 데이터 캡처 및 합성 전략
대규모 딥 러닝 시스템에는 레이블이 지정된 데이터가 많이 필요하다. 이 시스템의 경우 녹음 된 발화와 해당 영어 transcription이 많이 필요하지만 충분한 규모의 공개 데이터 셋이 거의 없다. 따라서 모델을 훈련하기 위해 9600명의 화자로부터 5000 시간의 읽기 음성으로 구성된 데이터 셋을 수집했다.
레이블된 데이터 셋 요약

4.1 Synthesis by superposition 중첩에 의한 합성
훈련 데이터를 더욱 확장하기 위해 우리는 효과적인 훈련 샘플 수를 확대하기 위해 데이터 합성을 사용한다. [37, 26, 6]. 이 작업에서 목표는 주로 기존 시스템이 잘 동작하지 않는 시끄러운 환경에서의 성능을 향상시키는 것이다. 그러나 시끄러운 환경에서 레이블된 데이터 (예 : 음성 읽기)를 얻는 것은 실용적이지 않으므로 이런 데이터를 생성하는 다른 방법을 찾아야한다.
우선 오디오 신호는 소스 신호의 중첩 과정을 통해 생성된다. 이 사실을 사용하여 시끄러운 환경에서의 훈련데이터를 합성할 수 있다.
예를 들어, 음성 오디오 트랙 x(i) 와 소음 오디오 트랙 ξ(i) 가 있는 경우 시끄러운 환경에서 포착된 오디오를 시뮬레이션한 “noisy speech” 트랙
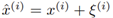 를 형성 할 수 있다. 필요한 경우 ξ (i) 또는 x (i)의 파워 스펙트럼에 잔향, 에코 또는 다른 형태의 제동을 추가한 다음 사실적인 오디오 장면을 만들 수 있다.
그러나이 접근 방식에는 몇 가지 위험이 있다. 예를 들어, 1000 시간의 깨끗한 음성을 취하고 1000 시간의 “noisy speech” 트랙을 생성하려면 약 1000 시간에 걸친 고유 한 소음 오디오 트랙이 필요하다. 따라서 1000 시간 길이의 단일 노이즈 소스 ξ (i)를 사용하는 대신 많은 수의 짧은 클립 (공개 비디오 소스에서 수집하기 쉬운)을 사용하고 모두를 중첩하기 전에 별도의 노이즈 소스로 처리한다.
를 형성 할 수 있다. 필요한 경우 ξ (i) 또는 x (i)의 파워 스펙트럼에 잔향, 에코 또는 다른 형태의 제동을 추가한 다음 사실적인 오디오 장면을 만들 수 있다.
그러나이 접근 방식에는 몇 가지 위험이 있다. 예를 들어, 1000 시간의 깨끗한 음성을 취하고 1000 시간의 “noisy speech” 트랙을 생성하려면 약 1000 시간에 걸친 고유 한 소음 오디오 트랙이 필요하다. 따라서 1000 시간 길이의 단일 노이즈 소스 ξ (i)를 사용하는 대신 많은 수의 짧은 클립 (공개 비디오 소스에서 수집하기 쉬운)을 사용하고 모두를 중첩하기 전에 별도의 노이즈 소스로 처리한다.  많은 신호를 중첩 할 때 실제 환경에서 녹음 된 노이즈의 종류와 다른 “노이즈”사운드로 끝날 수 있다. 합성 데이터와 실제 데이터 사이의 유사성을 보장하기 위해 각 주파수 대역의 평균 전력이 실제 노이즈 녹음에서 관찰된 평균 전력과 크게 다른 후보 클립은 제외했다.
많은 신호를 중첩 할 때 실제 환경에서 녹음 된 노이즈의 종류와 다른 “노이즈”사운드로 끝날 수 있다. 합성 데이터와 실제 데이터 사이의 유사성을 보장하기 위해 각 주파수 대역의 평균 전력이 실제 노이즈 녹음에서 관찰된 평균 전력과 크게 다른 후보 클립은 제외했다.
4.2 Capturing Lombard Effect
시끄러운 환경에서의 음성 인식 시스템이 직면하는 한 가지 도전적인 효과는 “롬바르도 효과”이다. 화자는 주변의 소음을 극복하기 위해 목소리의 음조나 굴절을 적극적으로 바꾼다. 쉽게 말하자면 사람들은 소음이 심한 환경에서 말을 할 때, 자신의 목소리가 좀 더 잘 들리게 하기 위해서, 자신도 모르게 말하는 방식에 변화를 주는 것이다. 훈련 데이터에서 이 효과가 표현되도록 하기 위해 발화를 녹음 할 때 착용한 헤드폰에 큰 소음을 재생하여 데이터 수집 중에 의도적으로 Lombard 효과를 유도하고 훈련 데이터에서 롬바드 효과를 포착할 수 있게한다.( 헤드폰과 컴퓨터 스피커를 통해 재생되는 소음을 실험했는데 헤드폰을 사용하면 배경 소음없이 “깨끗한”녹음을 얻을 수 있고 나중에 자체 합성 소음을 추가 할 수 있다는 장점이 있다.)
5. Experiments
시스템을 평가하기 위해 두 개의 실험을 수행했다. 두 경우 모두 표 2의 데이터 셋을 선택하여 학습된 모델을 사용하여 문자 수준의 전사를 예측한다. 예측된 확률 벡터와 언어 모델을 디코더에 입력하여 단어 수준의 전사를 생성하고, 이는 ground truth 결과와 비교하여 단어 오류율 (WER)을 산출한다.
5.1 Conversational speech: Switchboard Hub5’00 (full)
시스템을 이전 연구와 비교하기 위해 매우 까다로운 테스트 셋인 Hub5’00 (LDC2002S23)을 사용한다. 일부 연구자 들은 이 데이터 셋을 “easy”(Switchboard) 와 “hard”(CallHome)로 분리하여 종종 더 쉬운 부분에만 새로운 결과를 보고하지만 이 연구에서는 가장 도전적인 경우 인 전체 집합을 사용하고 전체 단어 오류율(WER)을 제시한다
300시간 Switchboard 대화형 전화 음성 데이터 세트에서만 학습한 모델과 Switchboard (SWB)와 Fisher (FSH) 3둘 다에서 학습한 모델을 평가했다. Since the Switchboard and Fisher corpora are distributed at a sample rate of 8kHz, we compute spectrograms of 80 linearly spaced log filter banks and an energy term. The filter banks are computed over windows of 20ms strided by 10ms. ( mel-scale log filter banks or the mel-frequency cepstral coefficients와 같은 정교한 기능은 평가하지 않았다.) 화자 적용은 현재 음성인식 시스템의 성공에 아주 중요하다.[44, 36] Hub5’00에서 테스트한 모델의 경우 화자 별로 스펙트럼 기능을 정규화하여 간단한 형태로 적용합니다. 디코딩을 위해 Fisher 및 Switchboard 필사본에 대해 훈련 된 30,000 단어 어휘가 포함 된 4 그램 언어 모델을 사용한다.
Deep Speech SWB 모델은 단 300 시간의 switchboard에서 훈련된 2048 개의 뉴런을 각각 가진 5 개의 은닉 계층으로 구성된 네트워크이다. Deep Speech SWB + FSH 모델은 전체 2300 시간 결합 말뭉치에서 훈련된 2304 개의 뉴런의 5 개의 은닉 계층을 각각 포함하는 4 개의 RNN의 앙상블이다. 모든 네트워크는 +/- 9 프레임의 입력으로 훈련된다.

Vesely et al. (DNN-GMM sMBR) [44]는 훈련 세트를 재정렬하기 위해 일반적인 하이브리드 DNN-HMM 시스템을 사용한 후 DNN 위에 시퀀스 기반 손실 함수를 사용한다. Hub5’00 테스트 세트에서 이 모델의 성능은 이전에 발표된 최고의 결과이다. 결합된 2300시간의 데이터에 대해 훈련되었을 때 Deep Speech 시스템은 이 기준선에서 절대 WER 2.4 %, 상대 13.0 % 향상된다.
Maas et al. (DNN-HMM FSH) [28] 모델은 Fisher 2000 시간 코퍼스에 대해 학습했을 때 19.9 % WER를 달성한다. 이 시스템은 오픈 소스 음성 인식 소프트웨어 인 Kaldi [32]를 사용하여 구축되었다. 비교 가능한 양의 데이터에 대해 교육을 받았을 때 Deep Speech가 최고의 기존 ASR 시스템과 경쟁할 수 있다.
5.2 Noisy speech
시끄러운 음성 성능을 테스트하기 위한 표준이 거의 없기 때문에 10명의 화자로부터 100 개의 시끄러운 발화와 100 개의 소음이 없는 발화로 구성된 자체 평가 세트를 구성했다. 소음 환경에는 배경 라디오 또는 TV가 포함되었다. (설거지, 붐비는 카페, 레스토랑, 빗속에서 운전하는 차 안) 발화 텍스트는 주로 웹 검색 쿼리 및 문자 메시지, 뉴스 스크랩, 전화 대화, 인터넷 댓글, 공개 연설 및 영화 스크립트에서 나왔다. 잡음이 있는 샘플의 신호 대 잡음비 (SNR)를 정밀하게 제어하지는 못했지만 2 ~ 6dB(데시벨) 사이의 SNR을 목표로 했다. 다음 실험에서는 표 2에 나열된 모든 데이터 세트 (7000 시간 이상)에 대해 RNN을 훈련한다. 각 패스에서 새로 합성된 노이즈를 사용하여 15 ~ 20 에폭을 훈련하기 때문에 모델은 100,000 시간 이상의 새로운 데이터에서 학습한다. 각각 2560 개의 뉴런으로 이루어진 5 개의 은닉층이있는 6 개의 네트워크 앙상블을 사용한다. 교육 또는 평가 세트에는 화자 적응 형태가 적용되지 않는다. 각 예제의 전체 파워를 일관되게 만들기 위해 발화별로 훈련 예제를 정규화한다.
The features are 160 linearly spaced log filter banks computed over windows of 20ms strided by 10ms and an energy term. 오디오 파일은 16kHz로 다시 샘플링되고 마지막으로, 각 주파수 빈에서 훈련 세트에 대한 전역 평균을 제거하고 전역 표준 편차로 나눈다. 따라서 입력이 훈련 초기 단계에서 잘 조정된다. 디코딩을 위해 5 그램 언어 모델을 사용한다. Common Crawl6의 2억 2천만 개의 구문에 대해 언어 모델을 학습한다. 각 구문의 문자 중 최소 95 %가 알파벳으로 선택된다. 가장 일반적인 495,000 단어만 유지되고 나머지는 UNKNOWN 토큰으로 다시 매핑된다.
Deep Speech 시스템을 (1) wit.ai, (2) Google Speech API, (3) Bing Speech 및 (4) Apple Dictation과 같은 여러 상용 음성 시스템과 비교했다.
우리의 테스트는 시끄러운 환경에서 성능을 벤치마킹하도록 설계되었습니다. 이 상황은 웹 음성 API를 평가하는 데 어려움이 있다. SNR(신호 대 잡음비)이 너무 낮거나 발화가 너무 긴 경우에 전혀 결과를 제공하지 않는다. 따라서 모든 시스템이 비어 있지 않은 결과를 반환한 발화의 하위 집합으로 비교를 제한한다. *(신호 대 잡음비(SNR)가 높으면 잡음이 적고 음질이 좋음.)
앞서 설명한 노이즈 합성 기술의 효율성을 평가하기 위해 두 개의 RNN을 훈련 시켰는데, 하나는 5000 시간의 원시 데이터에 대해 훈련되었고 다른 하나는 동일한 5000시간에 잡음을 더한 상태로 훈련했다. 100 개의 깨끗한 발화에서 두 모델은 각각 깨끗한 훈련된 모델과 잡음 훈련 된 모델에 대해 9.2 % WER 및 9.0 % WER를 거의 동일하게 수행한다. 그러나 100 개의 시끄러운 발화에서 잡음을 더해 학습한 모델 깨끗한 모델의 28.7 % WER에 비해 22.6 % WER, 6.1 % 절대 및 21.3 % 상대적 개선을 달성한다.

*괄호 안의 숫자는 채점된 발화 수이다.
6. Related Work 관련 연구
신경망 음향 모델 및 기타 연결 주의적 접근 방식은 1990 년대 초에 음성 파이프 라인에 처음 도입되었습니다 [1, 34, 11]. DNN 음향 모델 [30, 18, 9]과 유사한 이러한 시스템은 음성 인식 파이프 라인의 한 단계 만 대체합니다 우리 시스템은 딥 러닝 알고리즘에서 종단 간 음성 시스템을 구축하려는 다른 노력과 유사하다. Graves et al. [13] 이전에 생성 된 전사의 점수를 매기기위한 “연결주의 시간 분류”(CTC) 손실 함수를 도입했습니다. RNN과 LSTM 네트워크를 통해 이전에이 접근 방식을 음성에 적용했습니다 [14]. 우리는 훈련 절차의 일부에 대해 CTC 손실을 유사하게 채택하지만 훨씬 더 간단한 반복 네트워크를 사용합니다.
7. Conclusion 결론
이 논문에서는 두 개의 시나리오(명확한 대화 내용, 시끄러운 환경에서 음성)에서 기존의 최첨단 인식 파이프라인을 능가할 수 있는 end-to-end 딥러닝 기반 음성 시스템을 제시하고 있다. 이 논문에서의 접근 방식은 다중 GPU 학습과 데이터 수집 및 합성 전략을 통해 시스템이 처리해야하는 왜곡 (예 : 배경 소음 및 롬바드 효과)을 나타내는 대규모 교육 셋을 구축 할 수 있다. 이런 방법을 결합하면 기존 방법보다 한 번에 더 나은 성능을 발휘하는 데이터 기반 음성 시스템을 구축할 수 있으며 복잡한 처리 단계에 의존하지 않게 된다. 앞으로 증가할 컴퓨팅 성능과 데이터 셋의 크기를 활용함에 따라 계속 개선될 것이다.
댓글남기기