
Mozilla DeepSpeech
2017년 12월 모델과 데이터셋 공개.
2020년 12월 19일 업데이트 자료를 참고하여 작성
중국 바이두 연구소의 Baidu Deep Speech를 모태로 한 오픈소스 음성 인식 엔진이다. 소스 코드가 모태는 아니고, 기계학습 모델 논문을 참고한 것이다. Tensorflow를 활용하였으며 사이트에서 레시피를 제공하고 있다.


ARCHITECTURE AND TRAINING
이 프로젝트의 목표는 간단하고 개방적이며 유비쿼터스(simple, open, and ubiquitous) 음성 인식 엔진을 만드는 것이다. 엔진을 실행하는데 서버 급 하드웨어가 필요하지 않다는 점에서 간단하다. 코드와 모델이 Mozilla Public License에 따라 출시된다는 점에서 개방적이다. 엔진이 여러 플랫폼에서 실행되고 다양한 언어에 대한 적용할 수 있어야 한다는 점에서 유비쿼터스하다. 엔진의 아키텍처는 원래 Deep Speech : Scaling up end-to-end 음성 인식에 의해 동기가 부여되었으나 현재 엔진은 원래의 엔진과 많은 측면에서 다르다. 엔진의 핵심은 음성 스펙트로그램을 수집하고 영어 텍스트 필사본을 생성하도록 훈련된 RNN이다.
Deep speech는 소음환경, 잔향, 화자변이에 매우 좋다. 음소(Phoneme) 사전 구축이 필요없고 음소라는 개념도 불필요하다. 발음 사전(lexicon) 단위의 변환을 거치지 않는다. 종단 간 학습을 이용한 음성인식은 주어진 음성을 음소 및 형태소를 거치지 않고 바로 단어나 문장으로 변환할 수 있다.) 여러 중간 단계들을 생략해 음소 단위로 훈련을 할 필요 없다. 오디오 특징(feature)을 입력으로 하고 일련의 글자(character) 혹은 단어들을 출력으로 하는 방식으로 수행한다.
종단간 학습 모델은 음성(raw waveform) 그리고 이에 해당하는 텍스트 (text)만 있는 데이터를 가지고만 모델을 학습시킨다. 일단 이러한 학습 데이터를 넣어주면 중간 과정 필요없이 모델이 알아서 다 배울 수 있고 최종출력은 KenLM을 활용하여 교정한다.
학습 세트에서 단일 발화 $x$와 레이블 $y$를 샘플링한다.
\(S = {(x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)}), \cdots}\)
$x^{(i)}$ 각 발화는 길이 $T^{(i)}$의 시계열 데이터이다. - $(i)$는 수많은 데이터셋 중에 $i$번째 데이터셋
모든 시간 조각은 오디오 기능의 벡터이다. 모델은 MFCC를 사용한다. 입력 $X$와 정답 $Y$가 있다면 $X$는 $t$초마다 $p$번째 주파수의 크기를 나타내는 스펙트로그램[1] 형태의 데이터이고 아래와 같이 표현할 수 있다.
\[x^{(i)}_{t,p}=1,\cdots, T^{(i)}\]RNN의 목표는를 $\hat{y}_t=P(c_t|x)$이용해 입력 시퀀스 $x$를 전사 $y$에 대한 문자 확률 시퀀스로 변환하는 것이다.
\(c_t \in {a,b,c, \cdots, z, space, apostrophe, blank}\)
이 시스템의 RNN 모델은 총 5개의 은닉 유닛 계층으로 구성되어있다.
$h(0)$: 입력 $X$
$h(l)$: 계층 $l$의 은닉 유닛
이 모델에서 1~3층은 반복되지 않는다. 첫 번째 레이어의 경우, 각 시간 t에서의 출력은 MFCC frame $Xt$ 와 context of $C$에 따라 다르다. (모델은 C=9 사용) 나머지 비 순환 계층은 각 시간 단계에 대해 독립적인 데이터에서 작동한다. 따라 처음 3개의 레이어는 다음과 같이 계산된다.
\(h^{(l)}_t=g(W^{(l)}h^{(l-1)}_t)+b^{(l)}\)
*MFCC(Mel-Frequency Cepstral Coefficient) 음성/음악 등 오디오 신호 처리 분야에서 널리 쓰이는 특징값(Feature) 중 하나이다. MFCC는 오디오 신호에서 추출할 수 있는 feature로, 소리의 고유한 특징을 나타내는 수치이다. 주로 음성 인식, 화자 인식, 음성 합성, 음악 장르 분류 등 오디오 도메인의 문제를 해결하는 데 사용된다.
여기서 $W^{(l)}, b^{(l)}$는 계층 l의 가중치 행렬과 편향 매개 변수이고, 활성화 함수는 clipped ReLu로 0 ~ 20 사이의 값만 사용한다.
\[g(z) = min\{max\{0, z\}, 20\}\]네 번째 층은 순환 계층이다. 이 계층에는 순방향 반복 은닉 유닛이 포함된다.
\[h_t^{(f)}=g(W^{(4)}h_t^{(3)}+W_r^{(f)}h^{(f)}_{t-1}+b^{(4)})\]h^{(f)}는 $i$번째 발화에 대해 $t=1$에서 $t=T(i)$ 까지 순차적으로 계산되어야 한다.
다섯 번째 비 순환 계층은 순방향 유닛을 입력으로 사용한다.
\[h^{(5)}=g(W^{(5)}h^{(f)}+b)\]출력 계층은 알파벳의 각 시간 슬라이스 t 와 문자 k 에 대해 예측된 문자 확률에 해당하는 표준 logit이다.
\[h^{(6)}_{t,k}=\hat{t,k}=(W^{(6)}h_t^{(5)}+b_k^{(6)})\]예측 $\hat{y}_{t,k}$을 계산하고 나면 CTC loss $L(\hat{y}, y)$를 계산하여 예측의 오류를 측정한다. (CTC 손실은 문자 간의 전환을 나타내기 위해 위의 공백이 필요하다.) 훈련 중에 ground-truth 문자 시퀀스 y가 주어지면 네트워크 출력과 관련하여 기울기 $L(\hat{y}, y)$를 평가할 수 있다.
이 시점에서 모든 모델 매개 변수에 대한 기울기 계산은 나머지 네트워크를 통한 역전파를 통해 수행될 수 있다. 훈련을 위해 Adam 방법을 사용한다.
전체 RNN 모델의 그림은 다음과 같다.
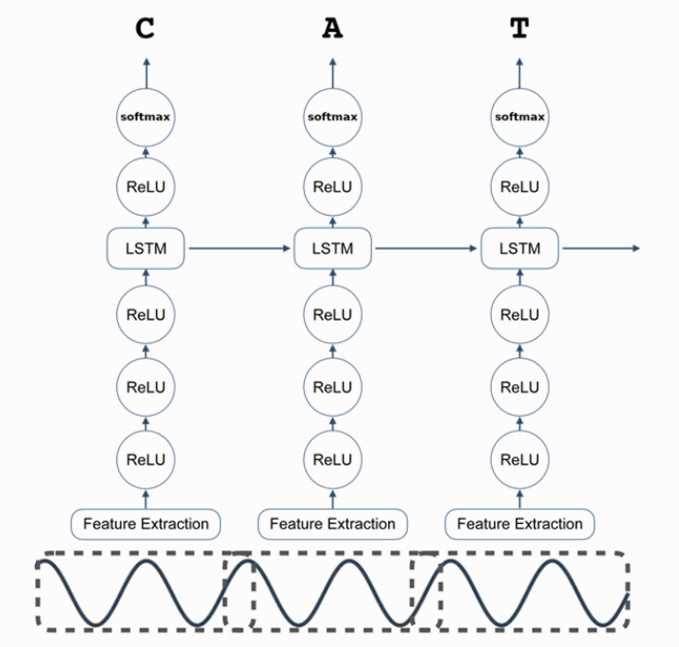
Geometric Constants - 네트워크와 관련된 몇 가지 상수
1. n_input
최대 n_steps 벡터의 각각은 음성 샘플의 시간 분할 영역의 MFCC 특징 벡터이다. 데이터 세트의 샘플 속도에 따라 MFCC 특징의 수를 정한다. 일반적으로 샘플 속도가 8kHz이면 13 가지 특징을 사용하고, 샘플 속도가 16kHz이면 26 개의 특징을 사용한다. n_input에서 벡터의 차원, 즉 MFCC 특징의 수를 캡처한다. n_input은 기본적으로 26이다.
2. n_context
RNN에서는 time-slice의 MFCC 특징과 함께 해당 프레임 양쪽의 C 프레임 컨텍스트가 제공된다.
n_context는 기본적으로 9이다.
일부 비 순환 계층: 각 계층의 유닛 개수만 지정하면 된다.
3. n_hidden_1, n_hidden_2, n_hidden_5
각각 첫 번째 계층, 두 번째 계층의, 다섯 번째 계층의 유닛 수를 말한다. “forward in time” 동작 하는 LSTM RNN으로 구성된다. ( LSTM 장치를 연결하는 위쪽 선인 “cell state” 차원은 입력 차원과 무관하다.)

4. n_cell_dim
입력 차원에 관계없이 “cell state” 차원을 자유롭게 선택할 수 있다.
5. n_hidden_3
LSTM세 번째 계층의 유닛 수는 다음과 같이 n_cell_dim에 의해 결정된다.
6. n_hidden_6
변수 n_hidden_6는 대상 언어의 문자 수에 1(공백)을 더한다
영어 카디널리티 세트: {a,b,c, …,z,space,apostrophe,blank}
Parallel Optimization(병렬 최적화)
단일 호스트의 GPU에서 DeepSpeech 모델의 최적화를 구현하는 방법이다. 병렬 최적화는 다양한 형태가 있다.
모델의 비동기 업데이트, 모델의 동기 업데이트 혹은 둘 다 사용할 수도 있습니다.
1. Asynchronous Parallel Optimization 비동기 병렬 최적화
예를 들어 비동기 병렬 최적화에서는
-
처음에 모델을 CPU 메모리에 배치한다.
-
각 GPU는 현재 모델 매개 변수와 함께 데이터의 미니 배치를 얻는다.
-
이 미니 배치를 사용하여 각 GPU는 모든 모델 매개 변수에 대한 기울기를 계산한다.
-
GPU가 작업을 완료되면 기울기를 CPU로 다시 보낸다.
-
CPU는 GPU로 부터 기울기 세트를 수신할 때마다 모델 매개 변수를 비동기적으로 업데이트한다.
-
장점
- 처리량: 어떤 GPU도 유휴 상태로 대기하지 않는다.
- GPU가 미니 배치 처리를 완료하면 처리할 다음 미니 배치를 즉시 얻을 수 있다.
- 미니 배치를 완료하기 위해 다른 GPU를 기다릴 필요가 없다.
-
단점
-
모델 업데이트가 비 동기식이므로 문제가 있을 수 있다.
예를 들어,
- CPU에 모델 매개 변수 w 가 있고 미니배치 n 을 GPU 1에 보내고 미니배치 n+1 을 GPU 2에 보낸다.
2) 비동기 처리방법이기 때문에 GPU 2가 GPU 1보다 먼저 완료될 수 있고 CPU의 모델 매개 변수를 업데이트 할 수 있다. 결과적으로 새 모델 매개 변수가 생성되는데 식은 아래와 같다.
\[\delta W_{n+1}(W), W + \delta W_{n+1}(W)\]3) 그 다음 GPU 1은 미니 배치를 완료하고 매개 변수를 다음과 같이 업데이트 한다.
\[W + \delta W_{n+1}(W), W + \delta W_{n}(W)\]여기서 문제는 $\delta W_n(W)$가 W에서 평가된다는 것이다. 따라서 기울기가 잘못된 위치에서 평가되기 때문에 약간 부정확할 수 있다. 이는 모델의 동기 업데이트를 통해 대응할 수 있지만 여전히 문제는 있다.
2. Synchronous Optimization 동기 최적화
동기 최적화는 위의 문제를 해결한다. 동기 최적화에서는,
- 모델을 CPU 메모리에 배치한다.
- G GPU 중 하나에 현재 모델 매개 변수와 함께 데이터의 미니 배치가 제공된다.
- 미니 배치를 사용하여 GPU는 모든 모델 매개 변수에 대한 기울기를 계산하고 기울기를 CPU로 다시 보낸다.
- CPU는 모델 매개 변수를 업데이트하고 다음 미니 배치를 보내는 작업을 한다.
-
장점
- 잘못된 기울기 업데이트 문제가 없다.
-
단점
- 한 번에 하나의 GPU 만 사용할 수 있다.
- 따라서 다중 GPU 설정이 있는 경우(G>1), GPU 중 하나를 제외하고 모두 유휴 상태로 유지된다.
3. Hybrid Parallel Optimization 하이브리드 병렬 최적화
비동기 및 동기 최적화의 대부분의 장점을 결합한 방법이다. 여러 GPU를 사용할 수 있지만 비동기 최적화로 인한 잘못된 기울기 문제가 발생하지 않는다.
하이브리드 병렬 최적화에서
-
모델은 CPU 메모리에 배치된다.
-
비동기 최적화와 같이 G GPU는 현재 모델 매개 변수와 함께 데이터의 미니 배치를 얻는다.
-
각 GPU의 미니 배치를 사용하여 모든 모델 매개 변수에 대한 기울기를 계산하고 기울기를 CPU로 다시 보낸다.
-
비동기 최적화와 달리 CPU는 각 GPU가 완료될 때까지 기다린다.
-
G GPU의 평균 기울기로 모델을 업데이트한다.

-
장점
- 비동기 병렬 최적화와 마찬가지로 여러 GPU를 병렬로 사용할 수 있다.
- 잘못된 기울기 문제가 없다. (실제로 단일 미니 배치로 작업하는 것처럼 수행된다.)
-
단점
- 하이브리드 병렬 최적화는 완벽하지 않다.
- 하나의 GPU가 다른 모든 GPU보다 느리면 이 GPU가 미니 배치를 완료할 때까지 나머지는 유휴 상태에 있어야한다. 이는 처리량을 저하시킬 수 있다.
- 모든 GPU의 제조사와 모델이 동일하다면 이 문제를 최소화할 수 있다.
상대적으로 하이브리드 병렬 최적화는 더 많은 장점과 적은 단점이 있기 때문에 하이브리드 모델을 사용한다.
Adam 최적화
Nesterov의 Accelerated Gradient Descent가 사용된 Deep Speech: Scaling up end-to-end speech recognition와 달리 일반적으로 미세 조정이 덜 필요한 Adam 최적화 방법을 사용한다.
[1] *스팩트로그램: 소리의 스펙트럼을 시각화해 그래프로 표현하는 기법. 파형(시간상 진폭 축의 변화)과 스펙트럼(주파수상 진폭 축의 변화)의 특징이 모두 결합된 구조로 시간 축과 주파수상의 따른 진폭의 차이를 농도나 표시 색상으로 나타낸다.
Reference
https://deepspeech.readthedocs.io/en/v0.9.3/index.html
댓글남기기